这篇论文描述了YouTube的一个召回和排序模型,是整个推荐系统的一部分,但是也比较完整,从数据处理、召回 到排序生成最终的推荐列表都有描述,是学习一个推荐系统的绝佳材料,其中很多细节也很值得学习。
架构
推荐系统整体架构如下图所示:
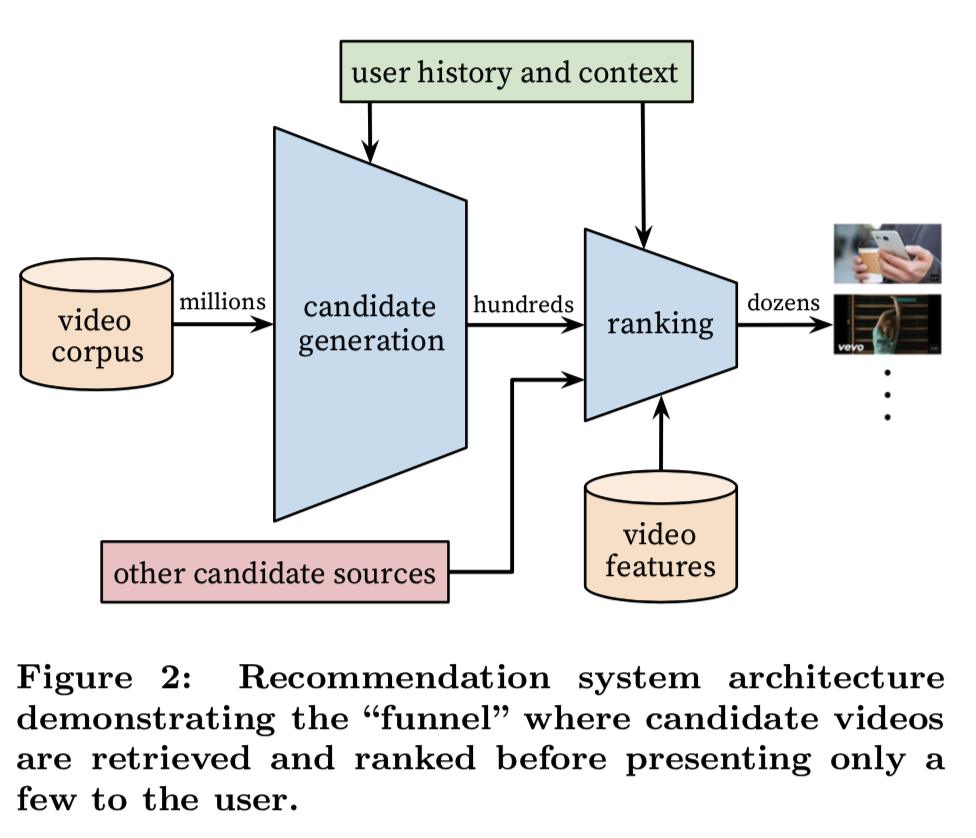
架构分为两个步骤:从视频库(百万级)中筛选出一小部分用户喜欢的视频(约几百个),称为召回,然后再对这 些视频打分排序输出最高的几十个,称为排序。召回是初步筛选,目的是大幅减少候选集减少排序的计算量,所用 的特征较少,模型也相对简单些。排序是精选,由于候选集已减少到几百个,可以使用更复杂的特征和模型。分为 这两步还有一个好处就是可以与其它召回策略组合。
召回
召回的目的就是从数百万个视频中筛选出与用户最相关的几百个视频,所以面临如下两个挑战:
- 召回率要足够高
- 计算速度要快
模型的设计
召回模型的设计主要受上一代推荐模型矩阵分解和NLP领域词向量模型的启发。矩阵分解模型根据用户对视频的行 为来表达用户与视频的关系,这样可以对相似的用户推荐相似的视频,是一种协同过滤算法,不需要学习视频的语 义,难度会小很多,缺点是只能推荐已经有人播放过的视频,无法解决视频的冷启动问题。矩阵分解可以看作是浅 层的神经网络,模型的迭代是在此基础上可以增加深度和宽度增加模型的表达能力。
召回问题可以看作是一个多分类问题,给定用户$U$和上下文$C$预测观看视频库$V$中某个视频$v_i$的概率:
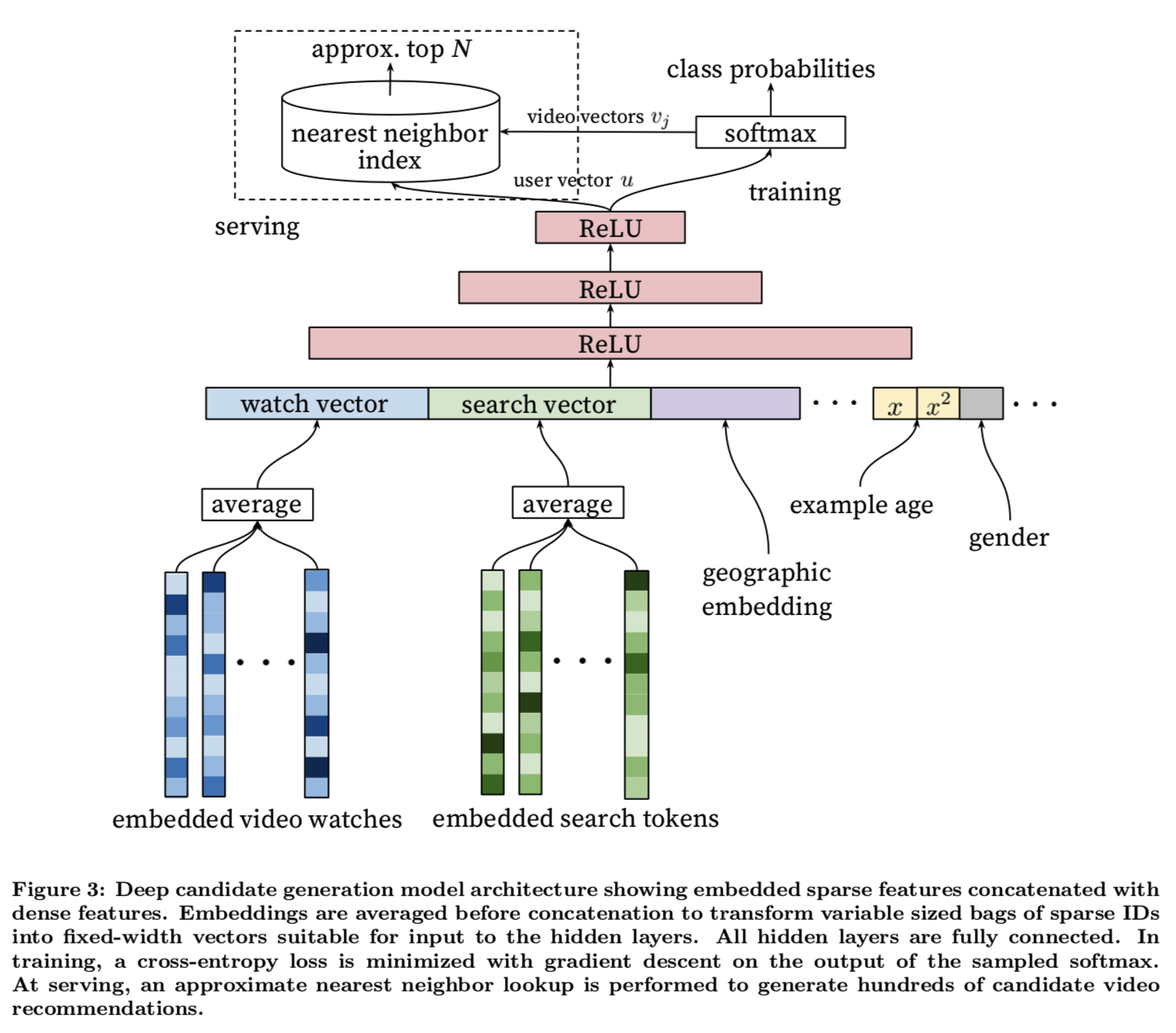
其中$u\in\mathbb{R}^N$(论文中$N=256$)是描述用户和上下文的向量,$v\in\mathbb{R}^N$是描述视频的向量。 这个模型的目标就是从用户的特征和上下文学习到用户的向量表达用于区分对不同视频的偏好。剩下的问题就是如 何得到视频向量,要保证视频向量能表达出与用户向量之间的关系。受NLP领域词向量模型的启发我们可以在同一 个模型中学习视频的向量,这样就可以保证视频向量与用户向量的距离可以描述两者之间的关系。
使用$z_i = v_i^Tu$,则可计算softmax交叉熵的损失函数为:
其中$y_i$表示样本label中的第$i$个分量,只有一个分量是1(对应于正样本),其它分量是0(对应于负样本),所以:
对参数求导求其梯度可得:
上述第二个式子需要对整个视频库求和,计算量非常大,但我们看出它其实是一个概率均值:
其中$P$表示$P(i|U,C)$. 我们可以采用importance sampling来简化对这个式子的计算。预定义一个采样分布$Q$ 从视频库的一个比较小的子集$V’$(数千个)中采样,我们可以近似计算:
特征工程
召回主要使用了用户近期行为(最近观看过的视频和搜索串)和人口学特征。近期观看过的视频通过视频向量求平 均值作为输入。搜索串另外用语言模型训练出词向量然后求平均值输入。人口学特征有助于解决冷启动用户的推荐 问题。用户的地理位置、设备使用one-hot编码向量作为输入。年龄、性别及登陆态作为连续变量归一化到$[0, 1]$.
用户一般喜欢看新上传的视频,而且视频在不同时间点的点击率也很不一样,所以模型必须能够表达出点击偏好与 时间之间的关系。因此必须输入一个与时间有关的特征,这个特征能表达出过去观看行为与未来预测之间的时间差。 论文中是以当前训练时间为基点计算样本的年龄(即训练时间减去样本时间),预测时输入即将预测的样本的年龄 (预测时间减去训练时间,为0或一个较小的负数)。
训练和评估
推荐系统解决的往往是一个代理问题而不是真实的目标问题(推荐的目标是找到让用户满意的视频,但是用户的满 意度是无法衡量的,所以召回模型退而求其次去优化点击率)。代理问题的存在会极大影响线上AB测试的性能,但 是离线评估时很难衡量。所以特征和样本的选择需要仔细权衡,不能导致过于拟合代理问题反而恶化真实目标。
训练的样本不仅仅包括推荐系统的结果,还包括其它路径的观看结果。这样是为了避免推荐系统的偏见,无法推出 新的内容。如果用户从其它途径观看了视频,我们也希望可以通过协同过滤学习到这个行为把视频推荐给其它用户。 为了防止过拟合代理问题,有时候还需要对模型隐瞒一些信息。比如用户搜索一个查询串后会出现跟这个查询串相 关的视频,如果把这个当成样本给模型学习会导致预测的下一个观看视频就是上次搜索过的视频,这个并不是用户 想要的。构造样本时把查询串的顺序信息丢掉可以避免这个问题。
用户观看视频通常会表现出非对称行为。比如观看系列视频往往从第一集开始看起,而不是反过来。为了让模型学 习到这种规律,构造样本时也要保留这个顺序,而不是用未来的观看行为来预测过去的行为。
模型的网络结构像一个塔一样,第一层最宽,而后逐渐变窄,最后一层最窄。先从最简单的2层(包括输出层)开 始训练,逐渐增加深度和宽度,直到收益递减而收敛变慢为止。最终的网络结构如下所示:
排序
排序的目标是根据曝光预测观看视频的时长,使用时长而不是点击率更加符合业务目标。排序模型可以使用更多的 特征,因为候选的视频只有数百个。
输入特征主要分为两类:分类特征和连续特征。分类特征转化为一个稠密的向量表示,每个独立的特征空间都有自 己的向量空间,向量的纬度正比于特征空间的秩。如果特征空间的秩很大(比如视频和搜索串),则按点击频率取 最高的一部分,其余特征的向量取0. 多个分类特征的向量表达取其平均值。神经网络对连续特征的分布和取值范 围很敏感,所以需要归一化。连续特征都在训练之前根据其分布均匀归一化到$[0, 1]$(所谓均匀归一化是指归一化 后的每个取值的频率都相等)。另外,连续特征在归一化后还会取起平方和平方根以学习非线性规律。
为了预测观看视频的时长,模型的目标是加权的逻辑回归,即在计算逻辑回归的交叉熵损失函数时,正样本用观看 时长加权,而负样本使用1加权,则其损失函数为:
相当于一个正样本重复了$T_i$次,于是逻辑回归模型学习到的odds是:
所以预测时采用$\exp$作为最后一层的激活函数。
迭代模型时于召回模型一样,逐步增加深度和宽度并观察线上测试效果,同时要兼顾模型预测耗时。
![]()
Conclusions
论文中的模型虽然没有特别的创新之处,但是很多工程细节包括学习目标的设计、特征和样本的选择、模型的迭代 设计等却非常值得我们学习。